ГЕДЕЛЬ, ЭШЕР, БАХ: эта бесконечная гирлянда.
Перевод и типогенетическии код.
Читатель может спросить, откуда берутся энзимы и цепочки, и как можно узнать, к какой букве прикрепляется в начале каждый данный энзим. Чтобы найти ответ на второй вопрос, можно попробовать взять наудачу несколько цепочек и посмотреть, как действуют на них и на их «потомков» различные энзимы. Это напоминает головоломку MU, в которой мы начинали с некоей аксиомы и нескольких правил. Единственная разница заключается в том, что после того, как энзим обработал первоначальную цепочку, она утрачивается навсегда. В головоломке MU при получении MIU из MI строчка MI остается невредимой.
Однако в типогенетике, так же как и в настоящей генетике, мы имеем дело с гораздо более сложной схемой. Мы так же начинаем с неких случайных цепочек, подобных аксиомам формальных систем. Но теперь у нас нет «правил вывода» — то есть энзимов. Однако, мы можем перевести каждую цепочку в один или несколько энзимов! Таким образом, сами цепочки будут указывать нам, какие операции должны производиться на них, и эти операции, в свою очередь, произведут новые цепочки, которые укажут на следующие операции, и т. д, и т. п! Вот так смешение уровней! Для сравнения подумайте, насколько изменилась бы головоломка MU, если бы каждая новая теорема могла бы быть превращена в правило вывода при помощи некоего кода.
Как же делается подобный «перевод»? Для этого используется типогенетический код, при помощи которого соседние пары оснований — так называемые «дублеты» представляют различные аминокислоты. Существует шестнадцать возможных дублетов АА, AC, AG, AT, CA, СС и т. д. С другой стороны, у нас есть пятнадцать аминокислот. Типогенетический код показан на рис 87.
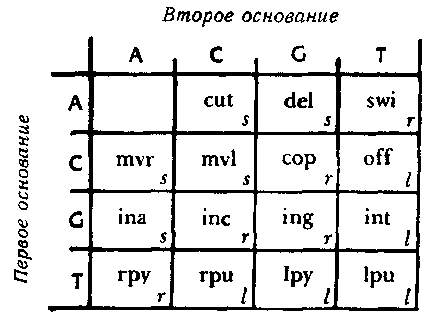
Рис. 87. Типогенетический код, при помощи которого каждый дублет кодируется как одна из аминокислот (или как знак препинания).
Из таблицы следует, что перевод дублета GC — «vsc» («вставить С»); что AT переводится как «prb» («перебросить энзим на другую цепочку») и так далее. Таким образом, становится ясно, что цепочка может прямо определять энзим. Например, цепочка:
ТАGАТССАGТССАСАТСGА.
Разделяется на дублеты следующим образом:
ТА GA ТС CA GT СС AC AT CG А.
Последнее А остается без пары. Вот перевод этой цепочки в энзимы:
Рmр — vsa — ргр — sdp — vst — sdl — raz — prb — kop.
(Заметьте, что оставшееся А ничего не добавляет).